Mirror Mirror
Reflections on Quantitative Fairness
NOTE: This document is a work in progress and comments are highly appreciated. Also, for now it looks best on a computer. There isn’t really any good reason for that and we hope to improve the experience on smaller screens soon. —Shira (sam942@mail.harvard.edu, @shiraamitchell) and Jackie (dont@email.me)
- Introduction
- Setup
- Definitions: Metric Parities
- Definitions: Conditional Independence
- Definitions: Causality
- Plurality
- Connections
- Directions
- Appendix 1: Other Resources
- Appendix 2: List of definitions
Introduction
How do you know when you’re being fair? How do you know when you’re being treated unfairly? To answer this question we can look to ethical, philosophical, political, and legal conversations, where fairness has been articulated and argued for centuries, often in a highly formalized setting. In this document we are concerned with new entries to the topic of fairness by statisticians, machine learning researchers, and other quantitative experts. We refer to this as the quantitative fairness conversation. We hope to survey a few of the available quantitative articulations of fairness, and to illustrate some of their tensions and limitations.
Fairness and Civil Rights
The 20th century was marked by a number of legal and legislative attempts to rectify injustice, inequality, and polarization along social axes such as race, gender, and class. These projects inevitably faced issues in articulating and formalizing principles of fairness and we would like to single out an example in a US political context (we largely work in this context without comment and regard it as a serious omission).
The Civil Rights Act of 1964 and the Fair Housing Act of 1968 outlined theories of procedural unfairness under which a person may bring suit. The exact jurisprudential details are beyond our expertise, but it is helpful to focus on Title VII of the Civil Rights Act. Title VII has been interpreted to provide recourse against employers in two settings [Barocas and Selbst]:
- Disparate treatment: the formal use of group membership or intent to treat (members of) groups differently.
- Disparate impact: facially neutral procedures that have a disproportionately adverse outcome in some groups.
To give an example of the concepts in the fair housing setting, imagine two cases of redlining. Suppose a lender denies loans to black applicants on the basis of their race. This would qualify as disparate treatment. Now consider a lender with no intention to consider race, but who uses neighborhood average income as a signal of creditworthiness. If black applicants live in comparatively poor neighborhoods, fewer black applicants receive loans. This might be an example of disparate impact.
Since we are not lawyers, we prefer not to say too much about the legal interpretations of these criteria. In some ways, what matters is that there are several. In other words, that the relevant principle of fairness may be an ensemble of more fundamental principles. This raises a number of questions such as:
- Incompleteness: is my ensemble complete? Perhaps there’s a notion I’ve missed.
- Error: does my ensemble contain errors? Perhaps one of my notions is completely wrong in certain situations where I never thought to apply it.
- Unexpected Consequences: does my ensemble have unexpected entailments? Sometimes a compact set of assumptions can lead to surprising and counterintuitive results.
- Mutual Incompatibility: is it possible to satisfy them all? Perhaps there is a contradiction between my notions of fairness.
- Evaluation of Tradeoffs: in situations where not all notions of fairness can be satisfied, what’s the right way of trading off violations of each?
- Communication: is there any compact way of communicating my notions of fairness?
In the emerging field of quantitative fairness, we will meet all of these concerns again. We hope that our work can be part of a conversation that makes these concerns explicit.
Before we proceed to our exposition it may be helpful to explicitly address the most straightforward definition of fairness in a decision procedure:
- Fairness Through Unawareness: the decision procedure is not allowed to use group membership.
This principle is routinely applied. For example, there are many situations in housing or employment where certain information is regarded as inadmissible to collect or consider. But as we have seen in the example of redlining, it provides no guarantees against disparate impact. Moreover, it builds in no protection against disparate treatment via proxy variables.
Below, we survey quantitative definitions of fairness in the statistics and machine learning literature, organized as:
- assertions of metric parity
- assertions of conditional independence
- assertions of the absence of causal relationships
After this survey of definitions we discuss some of the ramifications of the zoo of conflicting definitions, and proceed to a number of applications and directions. Our approach is necessarily slanted by the authors’ background and expertise, noticeably omitting much discussion of either the social science literature, political philosophy, or activist conversations. It is our hope that this survey can animate the quantitative reader to take an interest in those conversations, which are in no way eclipsed by mathematical developments.
Setup
We are interested in evaluating both human and automated procedures (“algorithms”) through several yet-to-be-defined definitions of fairness. We narrow our discussion to procedures that are motivated by some unknown, future ground truth. Consider a procedure that is applied to a population of individuals, e.g. loan applicants or criminal defendants. Each of these individuals has a binary true status $Y$, e.g. loan default or criminal re-offense. When we apply the procedure to an individual, their true status is unknown. The procedure may output three different things:
- Decision: a binary decision $d$ that attempts to approximate $Y$.
- Probability: a real number $S$ that can be interpreted as an approximation to the probability that $Y=1$.
- Score: a real number $S$ without necessarily having any probabilistic interpretation, with some approximately monotone but unspecified relationship to probability.
As an example, if an individual is being considered for a loan, a decision tells you to approve or deny the loan, a probability might estimate the individual’s probability of default, while a score might be their credit score. Another example of a score might be fitted values from a logistic regression but we don’t actually believe in it as a model.
We can move among these three types of output as shown:
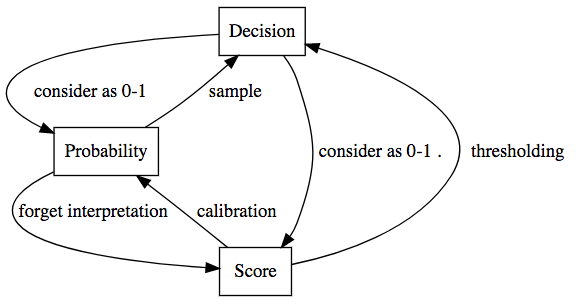
For each individual, we can define the variables:
| $Y$ - true status. | This is the true status. When we apply the procedure to an individual, their true status is unknown. But the procedure is hopefully based on the true statuses of other individuals from the same population (training data). It is also known as the target variable, dependent variable, outcome of interest, class label, or ground truth. |
| $A$ - group membership. | This is group membership, where the groups are based on legal or political concerns. In our examples, this is race, gender, or class. |
| $X$ - covariates. | These are the variables available to the procedure. They are also known as features, independent variables, inputs. |
| $d$ - decision. | This is a binary decision output. |
| $S$ - score. | This is a score (or probability) output. |
Definitions: Metric Parities
In machine learning and statistics, a classifier or model is a procedure that attempts to approximate the true status $Y$ based on past data (training data). The first set of fairness definitions we will consider are those that assert equal metrics of the classifier across groups. Different domains might emphasize different metrics. For example, in a medical test we might be highly concerned with false negative diagnosis (in which case a dangerous condition could go untreated), and with false positive diagnosis (which could result in an unnecessary and dangerous medical intervention). The plurality of metrics give rise to a plurality of fairness definitions.
Fairness for Decisions
For binary decision procedures, we can summarize a procedure with the confusion matrix, which illustrates match and mismatch between decision ($d$) and true status ($Y$). Its margins are fractions of data, expressed as probabilities. For example, $P[Y=1]$ is the fraction of individuals in the data that have positive status, and $P[Y=1~\vert~d=1]$ is the fraction of those with a positive decision who are actually positive.
Confusion Matrix
|
Positive Status $Y = 1$ |
Negative Status $Y = 0$ |
Prevalence ("base rate") $P[Y = 1]$ |
||
|
Positive Decision $d=1$ |
True Positive (TP) |
False Positive (FP) |
Positive Predictive Value (PPV), aka precision $P[Y = 1 \vert d = 1]$ |
False Discovery Rate (FDR) $P[Y = 0 \vert d = 1]$ |
|
Negative Decision $d = 0$ |
False Negative (FN) |
True Negative (TN) |
False Omission Rate (FOR) $P[Y = 1 \vert d = 0]$ |
Negative Predictive Value (NPV) $P[Y = 0 \vert d = 0]$ |
|
Positive Decision Rate $P[d = 1]$ |
True Positive Rate (TPR), aka recall, aka sensitivity $P[d = 1 \vert Y = 1]$ |
False Positive Rate (FPR) $P[d = 1 \vert Y = 0]$ |
Accuracy $P[d = Y]$ |
|
|
False Negative Rate (FNR) $P[d = 0 \vert Y = 1]$ |
True Negative Rate (TNR), aka specificity $P[d = 0 \vert Y = 0]$ |
For any box in the confusion matrix involving the decision $d$, we can define fairness as equality across groups. See the full list below. We note (and display via highlighting) that equivalent definitions of fairness emerge from pairs that sum to 1.
Here we consider three definitions based on equal classifier metrics across groups:
- Equal False Negative Rates: the fraction of positives which are marked negative in each group agree.
- Equal False Positive Rates: the fraction of negatives which are marked positive in each group agree.
- Equal Positive Predictive Values: the fraction of those marked positive which are actually positive in each group agree.
It is useful to take a moment to consider that these definitions are genuinely different, both mathematically and as principles of fairness.
We can also consider a definition that is not based on how well we approximate true status $Y$:
- Statistical Parity (equal positive decision rates): the fraction marked positive in each group should agree.
Fairness for Scores
For score outputs, which we’ll have much less to say about, we can consider the following initial definitions of fairness based on equal metrics across groups:
- Balance for the Positive Class: the average score assigned to positive members, $E[S ~\vert~ Y=1]$, should be the same across groups. If the score were 0-1 this would be equal true positive rates (equivalently, equal false negative rates).
- Balance for the Negative Class: the average score assigned to negative members, $E[S ~\vert~ Y=0]$, should be the same across groups. If the score were 0-1 this would be equal false positive rates (equivalently, equal true negative rates).
- Calibration: the fraction of those marked with a given score who are actually positive, $E[Y ~\vert~ S=s]$, should be the same across groups. If the score were 0-1, this would be equal positive predictive values and equal negative predictive values.
- AUC (Area Under Curve) Parity: the area under the receiver operating characteristic (ROC) curve should be the same across groups. The AUC can be interpreted as the probability that a randomly chosen positive individual ($Y = 1$) is scored higher than a randomly chosen negative individual ($Y = 0$).
As with binary decisions, there is no single metric. And as with binary decisions, definitions based on equality of metrics are different, both mathematically and as principles of fairness.
Suppose we wish to evaluate the fairness of a procedure for the population to which it is applied (e.g. defendants in particular jurisdiction). Suppose we have access to a sample of data from this population. We should ask two questions:
- is the sample representative of the population?
- are the measured values the true values?
We now describe how the very general statistical considerations of sampling and measurement can compromise assessments of fairness.
Sampling
To generalize from a sample to a larger population, we assume that those in the sample are similar to those not in the sample. Suppose we are interested in hiring rates in a population of people with mostly low incomes. But our sample consists only of people with higher incomes. If income is related to hiring, the hiring rate in our sample will be a biased estimate of the hiring rate in the population. We can attempt to adjust for this issue in many ways but cannot ignore it (see, for example, Chapter 8 of BDA3).
Measurement
Similarly compromising are issues of measurement. Suppose we wish to evaluate the false positive rate of a criminal justice risk assessment tool to predict offense. This requires the true status, offense. Suppose that instead of offense, our data only include arrests. We can regard arrest as a noisy measurement of offense. In doing so, we would need to take seriously not only the difference between arrest and offense, but the fact that this difference may be much worse for some groups. For example, if black people are arrested more often for crimes they did not commit, our evaluation of fairness is severely compromised [Lum].
Definitions: Conditional Independence
Some notions of fairness can be phrased naturally and compactly in terms of conditional independence. Unfortunately, these compact statements suffer from a few conceptual issues:
- Conditional independence statements frequently have non-obvious entailments.
- Conditional independence statements which are very different may be almost identical verbally and errors are frequent when they are expressed informally.
- It is often difficult, especially verbally, to distinguish between probabilistic/statistical/observational and causal dependence. We’ll talk a bit more about this later.
However, none of these constitute substantial objections to conditional independence as a framework, we simply want to point to some sharp corners.
The conditions are most naturally phrased in terms of Decisions, Groups, and Data. Decision and Group are just what we’ve been calling $d$ and $A$ above, but Data deserves a bit more explanation. It includes variables we use for fairness checks. It need not be exactly the covariates used by the procedure ($X$), but could be a subset of them, or the true status ($Y$), or even empty ($\varnothing$).
There are three types of conditional independence that we can imagine.
- $\textrm{Decision} \perp \textrm{Group} ~\vert~ \textrm{Data}$
- $\textrm{Data} \perp \textrm{Group} ~\vert~ \textrm{Decision}$
- $\textrm{Decision} \perp \textrm{Data} ~\vert~ \textrm{Group}$
We consider these in an example.
Example: College Admissions
Interpreting Conditional Independence
- $\textrm{Data}$ - SAT score
- $\textrm{Decision}$ - college admission
- $\textrm{Group}$ - gender
Interpreting $\textrm{Decision} \perp \textrm{Group} ~\vert~ \textrm{Data}$
This implies that at any fixed SAT score, the admissions decision will be independent of gender. This matches an intuition of avoiding “disparate treatment” but if the groups have different distributions of SAT scores it may produce a “disparate impact” in that one group is admitted at a much higher rate than the other.
Interpreting $\textrm{Data} \perp \textrm{Group} ~\vert~ \textrm{Decision}$
This implies that the distribution of SAT scores among admitted students of each gender is the same. Suppose we violate this principle and admitted women have lower scores than admitted men. In a sexist environment, this can be pretext for resentment.
Interpreting $\textrm{Decision} \perp \textrm{Data} ~\vert~ \textrm{Group}$
This implies that within each group, SAT score is independent of the admission decision. This might be a reasonable demand if we felt that the SAT ought to be irrelevant to admissions. But it is not a natural definition of fairness with respect to Group.
Here then, are a few definitions of fairness, organized by the type of conditional independence and by the choice of Data.
| Data: | $\textrm{Decision} \perp \textrm{Group} ~\vert~ \textrm{Data}$ | $\textrm{Data} \perp \textrm{Group} ~\vert~ \textrm{Decision}$ |
| Status - $Y$ | $d \perp A ~\vert~ Y$ Equalized Odds [Hardt et al.] Conditional Procedure Accuracy Equality [Berk et al.] Equal False Positive Rates and Equal False Negative Rates |
$Y \perp A ~\vert~ d$ Conditional Use Accuracy Equality [Berk et al.] Equal Positive Predictive Values and Equal Negative Predictive Values |
(A subset of) Covariates - $X$ |
$d \perp A ~\vert~ X$ Conditional Statistical Parity |
$X \perp A ~\vert~ d$ NAME??? |
Nothing - $\varnothing$ |
$d \perp A$ Statistical Parity |
Vacuous condition. |
First, we note that for each of these definitions involving a decision, one can consider a definition involving a score $S$. Second, and more importantly, we point out that there can be mathematical and moral tension across both rows and columns of this table.
We pause to consider an extended example of law school admissions, illustrating the interpretation of a few of these conditional independence statements.
Example: Law School Admissions.
Seven Forms of Conditional Independence
Suppose we are selecting incoming law students for an honors program, and wish to select those students who will be successful, defined by some grade threshold. Consider several choices of data on which to base fairness checks:
- $Y$ - actual success
- $X^{\textrm{construct}}$ - an idealized form of qualification, not assumed measurable
- $\textrm{LSAT}$ - LSAT score
- $\varnothing$ - no data at all
We define
- $d$ - decision: admission to honors program
- $A$ - racial group
For each type of data we can attempt to interpret the two kinds of fairness we saw in our chart, namely $\textrm{Decision} \perp \textrm{Group} ~\vert~ \textrm{Data}$ and $\textrm{Data} \perp \textrm{Group} ~\vert~ \textrm{Decision}$. This gives seven conditional independence statements all of which seem to be intensely politicized in a way we cannot resolve here. Consider some examples:
- $d \perp A ~\vert~ Y$ - for successful students, selection is independent of race.
- $d \perp A ~\vert~ X^{\textrm{construct}}$ - any relationship between race and decision is explainable by (possibly unmeasured) qualification.
- $\textrm{LSAT} \perp A ~\vert~ d$ - the distribution of LSAT scores among accepted students is identical across race groups.
- $d \perp A ~\vert~ \varnothing$ - the rate of acceptance is identical across race groups.
In discussions of fair hiring and admissions one can encounter all these notions. Conversations can easily fall into the mire of assuming or imposing one or another condition as though it were an obviously correct formalization of fairness, treating violations of that principle as moral or conceptual gotchas. The frustrating and repetitive stalemate of these conversations likely reflects both confusion and fundamentally different ideas of fairness.
Individual Fairness
Consider conditional statistical parity that conditions on all the covariates $X$. This definition is easily satisfied by the definition from the introduction:
- Fairness Through Unawareness: the decision procedure is not allowed to use group membership. Symbolically, this means that $d_i=d_j$ if $X_i=X_j$ for individuals $i,j$.
If fact, if the decision is a deterministic function of $X$, the two definitions are equivalent. A related definition is:
- Individual Fairness: $d_i \approx d_j$ if $X_i \approx X_j$ for individuals $i,j$.
We note that Friedler et al. define individual fairness using $X^{\textrm{construct}}$, the desired (but not perfectly observed) covariates at decision time.
Definitions: Causality
So far, we’ve discussed definitions of fairness only in probabilistic/statistical/observational terms. But both moral and legal notions of fairness are often phrased in causal language. And as you may have heard before, “correlation does not imply causation.” So what is to be done?
Thankfully, there are several approaches to studying causality. We cannot give an exhaustive introduction here and refer the interested reader to Pearl 2009, Hernan and Robins, and Imbens and Rubin. Nonetheless, for the reader who has not seen this sort of thing before we would like to give some idea.
Arguably the simplest approach to causality is to translate causal statements into counterfactuals:
- “Was I not hired because I was black?” $\leadsto$ “Would I have been hired if I were non-black?”
- “Is there an effect of race on hiring?” $\leadsto$ “Would the rate of hiring be the same if everyone were black? if no one were?”
We can introduce the notation $d(\textrm{black}), d(\textrm{non-black})$ be the decision if the individual had been black, non-black respectively. We can state the following three definitions of fairness in terms of these counterfactuals:
- Individual Counterfactual Fairness: $d_i(\textrm{black}) = d_i(\textrm{non-black})$ for individual $i$
- Counterfactual Parity: $E[d(\textrm{black})] = E[d(\textrm{non-black})]$
- Conditional Counterfactual Parity: $E[d(\textrm{black}) ~\vert~ \textrm{Data}] = E[d(\textrm{non-black}) ~\vert~ \textrm{Data}]$. Conditioning on a lot of Data approaches individual counterfactual fairness. [Kusner et al.]
In the hiring example, individual counterfactual fairness can be regarded as a negative answer to each individual’s question “would the decision have been different if I were not black?” Counterfactual parity provides a negative answer to the question “would the rates of diring be different if everyone were black?” Finally, conditional counterfactual parity answers the same question as counterfactual parity, but now stratified by some factors, e.g. the application’s education.
How to compute with counterfactuals:
Estimating causal effects from observed data
For each individual we only get to see one of their two counterfactuals (also known as potential outcomes), $d(\textrm{non-black})$ and $d(\textrm{black})$. For black individuals, how would we learn about $d(\textrm{non-black})$? Assume that individuals who match on residence and socioeconomic status at birth (call these variables $C$) are similar enough that the hiring rate if they had been non-black is the same across the actual race groups. So we can compute the hiring rate had they been non-black by just looking at the actual hiring rate among non-black individuals with $C=c$ (e.g., born in Astoria, family income at birth less than $70k):
The assumption that moved us from counterfactuals (the left hand side) to something computable from data (the right hand side) is called ignorability or unconfoundedness, with $C$ known as confounders. In math, $d(\textrm{non-black}) \perp \textrm{race} | C$.
Causal pathways
So far we’ve defined fairness in terms of the total effect of race on the decision. However, it is possible to consider some causal pathways from race to be fair. For example, suppose race affects education obtained. If hiring decisions are based on the applicant’s education, then race affects hiring decisions. It often helps to visualize causal relationships graphically.
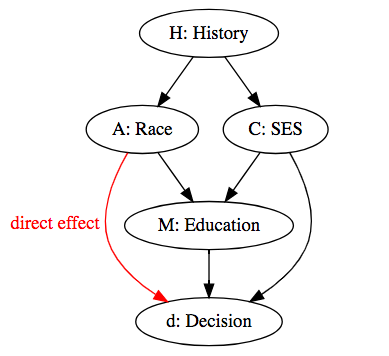
Following VanderWeele and Robinson and Jackson and VanderWeele, a complex historical process creates an individual’s race and socioeconomic status at birth. These both affect the hiring decision, possibly through mediating variables such as education. We can reason about effects along paths in this graph by defining fancier counterfactuals. Let $d(\textrm{non-black}, M(\textrm{black}))$ be the decision if the applicant had not been black, but education had remained the same. We can define
- No Direct Effect Fairness: $E[d(\textrm{black})] = E[d(\textrm{non-black}, M(\textrm{black}))]$
In other words, there is no average direct effect of race on hiring. But race is allowed to affect hiring through other variables (e.g., education). Scholars of causal inference (Pearl 2009, Nabi and Shpitser) see no direct effect fairness as the formalization of legal language. For example, from Carson v. Bethlehem Steel Corp.:
The central question in any employment-discrimination case is whether the employer would have taken the same action had the employee been of a different race (age, sex, religion, national origin, etc.) and everything else had remained the same.
Though this seems a reasonable translation from legal language to counterfactuals, we caution that such formalization excludes interpretations of the spirit of the law that may be useful politically and morally.
Beyond direct effects, one could consider certain paths to be fair or unfair. Two definitions from the literature include:
|
No Unfair Path-Specific Effects |
No Unresolved Discrimination |
|
| Paths considered unfair: | user-specified |
paths which are not blocked by resolving variables |
| What to check about paths? | average effect along path | presence of path |
Kilbertus et al. have a more restrictive designation of unfair paths. For example, in the diagram below, they do not allow a path through $M_1$ and $M_2$ to be unfair, but a path through only $M_2$ to be fair:
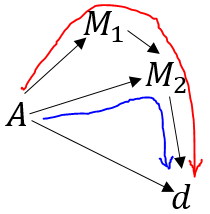
Three Types of Paths
Suppose we see a violation of the simple fairness definition of statistical parity. In our running hiring example, we can ask: why don’t black people get hired here? Causal reasoning offers three types of explanation, studied by Jackson and VanderWeele and Zhang and Bareinboim. We consider these explanations in the context of the graph for our hiring example:
- A direct effect of race on the decision, violating no direct effect fairness. In our example, being black directly causes people not to be hired due to prejudice.
- An indirect effect of race on the decision through other directed paths. In our example, being black causes fewer educational opportunities due to structural racism, which in turn causes them not to be hired due to the employer’s preference for a particular educational credential. If education credentials are considered fair to use in hiring, we satisfy no unfair path-specific effects (similarly, no unresolved discrimination).
- A back-door path: a path between race and the decision that starts with an arrow going into race “through the back door”, and so do not represent causal effects of race [Pearl 2009]. In our example, a complex historical process creates both race and socioeconomic classes in such a way that black people are generally born into low-income families. But a person’s race does not cause them to be born into a low-income family. Having a low socioeconomic status at birth causes fewer educational and hiring opportunities. Therefore, we expect an association between race and hiring that is not causal, and is explained by socioeconomic status at birth, a confounder.
The definitions of fairness based on the causal effect of race allow the third type of path. Therefore, if we have an intuition that such paths are unfair, we would need to require additional fairness constraints.
Causality and Agency
So far, we’ve been concerned with parities of decisions (be they counterfactual or statistical). Here we consider parities of agency. Returning to our hiring example, suppose non-black applicants can improve their hiring chances by taking a class, but black applicants see no such effect. This could create a sense of hopelessness among black applicants, while non-black applicants feel rewarded for their efforts. We can formalize a sense of equal reward for equal action using counterfactuals:
- Agency Parity:
Though not a notion of parity across groups, a goal could be high agency overall. This reflects very debatable intuitions about punishment, reward, and work, which deserve a fuller and more critical discussion than we can provide here.
Compared to counterfactual parity, which compared $d(\textrm{black})$ versus $d(\textrm{non-black})$, agency parity has the virtue of being theoretically measurable in a randomized trial. It may be more suited to philosophically conservative interpretations of causal reasoning, as we discuss below.
What sort of counterfactuals can we consider?
We may have a concern that certain counterfactual questions such as “what if one equaled zero?”, “what if a given statement were both true and false?”, or “what if this were all a dream?” lend themselves to a very different kind of reasoning than “what if a patient had been given a different medication?”, or “what if my credit score had been 800 instead of 600?”. Conservative philosophical and probabilistic interpretations of causality will sometimes restrict the variables and propositions that can be considered counterfactually, for example:
Hernan and Robins (Sections 3.4, 3.5) introduce counterfactuals as outcomes only under well-defined interventions, e.g. “if I had taken 150 mg of aspirin by mouth”. In contrast, Pearl 2009 (Section 11.4.5) allows counterfactuals under conditions without specifying how those conditions are established, e.g. “if I had not been black”. Greiner and Rubin and Kilbertus et al. both shift to proxies that may be easier to imagine as interventions, e.g. “if the name on my resume were changed to be atypical among black people”.
Plurality
Up to now, we’ve introduced several mathematical definitions of fairness. As with the plurality of legal notions of fairness, we now have a plurality of mathematical notions of fairness. We are faced with the same concerns as in the introduction.
In addition to the plurality of definitions of fairness, we are faced with a plurality of procedures. This can be described, in part, as choosing variables that are available to the procedure (what we’ve been calling $X$, the covariates/features).
We outline some ways to cope with plurality:
- Plurality of Definitions
- Philosophy and Politics: we could try to demonstrate that one or another definition of fairness is (situationally) appropriate or inappropriate, and pursue it at the cost of the others.
- Ensembles: we could try to satisfy several definitions of fairness simultaneously. Why not all of them?
- Plurality of Procedures
- Procedure Selection (Fairness as Constraint): after imposing a definition of fairness, we could try to choose the best procedure by some other criterion.
- Procedure Selection (Fairness As Objective): assuming the degree of deviation from fairness can be quantified, we can attempt to minimize this deviation.
We are unable to say much about the philosophical and political concerns here, but consider these issues live and debatable, with highly domain-specific conclusions.
In our discussion of ensembles, we survey a few negative results which have played a large role in the quantitative fairness conversation.
We frame our discussion of procedure selection in terms of the social phenomenon of redlining, and find that both forms of optimization are in play (if vaguely).
Plurality of Definitions: Ensembles and Impossibility
Suppose we try to cope with the plurality of fairness definitions by satisfying several definitions of fairness simultaneously. Consider that we could easily consider ensembles of fairness definitions which are stated in somewhat different languages. For example if we demand $E[d(\textrm{black}) - d(\textrm{non-black})] = 0$, $d \perp \textrm{race} ~\vert~ \textrm{SES},$ and equal false negative rates, the network of implications is by no means clear and there is no obvious common scale of violations for each.
Responding to these sorts of questions, Chouldechova proves that we cannot satisfy equal false negative rates, equal false positive rates, and equal positive predictive values, except under the condition of perfect prediction or equal base rates. Kleinberg et al. prove the essentially the same restriction for balance for the positive class, balance for the negative class, and calibration, as well as some extensions to the approximate and randomized settings, evidence that the theorem is somewhat robust.
Special Case:
Perfect Prediction and Equal Base Rates
There are two situations in which it’s easy to satisfy most of our definitions of fairness. Some authors call these trivial or degenerate cases, but we could just as well call them utopian cases.
- Perfect Prediction: the truth is generally believed to be fair. We might name this condition as $d = Y.$
- Equal Base Rates: if the groups are actually identical, then it’s very easy to achieve fairness by ignoring the group labels. Equationally, we might write this as $Y \perp A.$
Each of these situations can be regarded either as an unrealistic edge cases or as a political goal. We observe that the political translation of these conditions seem to be very different.
Plurality of Models: Feature Selection and Redlining
Redlining (wiki: Redlining) is defined as the denial of services to residents of certain areas based on the racial makeup of these areas. But what do we mean by based on? In cases of interest, this effect can occur both intentionally and unintentionally. For example, a discriminatory lender could deny housing loans to residents of a neighborhood which is known to be majority black, and could in a sense hide their anti-black racism behind a ZIP code. But one could produce similar effects unintentionally, for example by including average neighborhood income as a factor in a model of loan default, in a situation where black applicants mostly live in black neighborhoods that are on average economically depressed, while white applicants live in wealthier neighborhoods.
In this situation, a wealthy black person may be harmed by the choice to use the neighborhood income information, while a poorer white person may be helped by the choice to include it. So we see that the decision to include these variables in our model is not politically neutral, and that it is not necessarily clear that considering more variables produces a fairer outcome. It depends substantially on our notion of fairness.
Connections
COMPAS
The Context
Between arrest and trial, US criminal law leaves a lot of latitude to interpretation of whether accused individuals should be incarcerated, in what kind of facility, and for how long. There has been an increasing interest in either automating these decisions or including automated insights in decision making, in the form of risk scoring for “recidivism” or “re-offense” (one can object to both terms as creating an impression of certainty that there was a first offense).
This document began its life as an attempt to grapple with the debate around one such tool, COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), which is administered by the private company Equivant (formerly Northpointe). The tool outputs numerical scores, which are labeled, for example, “risk of recidivism”, “risk of violent recidivism”, or “risk of failure to appear”. These scores are then used in an unspecified way to make decisions of jail, bail, home arrest, release, etc.
Ideally in this situation one should ask for end-to-end transparency. We raise a number of questions:
- How was COMPAS developed? What training data are used?
- Are the COMPAS scores fair?
- In which jurisdictions are COMPAS scores used?
- In which decisions are COMPAS scores used?
- Who is training legal professionals in their interpretation of COMPAS scores?
- What are the implications of a selective or idiosyncratic use of COMPAS scores?
- What are the implications of depending on a company like Equivant/Northpointe?
- What is the process for auditing or removing a flawed tool?
It is the authors’ opinion that all such questions must be answered for any technology which is used. But for our purposes we will focus only on the second and ask: are the COMPAS scores fair as a matter of race?
The Debate
In 2016, Angwin et al. (methods: ProPublica) published a highly influential analysis based on data obtained through public records requests. Two of their findings can be phrased in our language as follows:
- COMPAS does not satisfy equal false negative rates, in fact, white defendants who did get rearrested were nearly twice as likely to be misclassified as low risk. [ProPublica]
- COMPAS does not satisfy equal false positive rates, in fact, black defendants who did not get rearrested were nearly twice as likely to be misclassified as higher risk. [ProPublica]
In their response, Equivant/Northpointe, the developers of COMPAS, cited two articles finding that:
- COMPAS satisfies calibration: scores mean the same thing regardless of the defendant’s race. For example, among defendants with a score of 7, 60 percent of white defendants were rearrested and 61 percent of black defendants were rearrested. [Flores et al.]
- COMPAS satisfies equal positive predictive values: among those labeled higher risk, the proportion of defendants who got rearrested is approximately the same regardless of race. [Northpointe]
Much of the subsequent conversation consisted of either trying to harmonize these definitions of fairness or asserting that one or the other is correct. For example, Feller, Pierson, Corbett-Davies, and Goel write in their Washington Post piece “A computer program used for bail and sentencing decisions was labeled biased against blacks. It’s actually not that clear.”:
It’s hard to call a rule equitable if it does not meet Northpointe’s notion of fairness. A risk score of seven for black defendants should mean the same thing as a score of seven for white defendants. Imagine if that were not so, and we systematically assigned whites higher risk scores than equally risky black defendants with the goal of mitigating ProPublica’s criticism. We would consider that a violation of the fundamental tenet of equal treatment.
But we should not disregard ProPublica’s findings as an unfortunate but inevitable outcome. To the contrary, since classification errors here disproportionately affect black defendants, we have an obligation to explore alternative policies. For example, rather than using risk scores to determine which defendants must pay money bail, jurisdictions might consider ending bail requirements altogether — shifting to, say, electronic monitoring so that no one is unnecessarily jailed.
Chouldechova has written on the trade-offs among equal false negative rates, equal false positive rates, and equal positive predictive values. Kleinberg et al. treat similar material. We mentioned this work above in our chapter on Ensembles and Impossibility.
As part of the conversation, ProPublica also responded to criticisms here:
- ProPublica’s response to Equivant/Northpointe
- ProPublica’s technical response to Equivant/Northpointe.
- ProPublica’s response to [Flores et al.].
Commentary
Why is this work so difficult to do? ProPublica’s analysis, and many papers in the field, rely on the same data obtained through public records requests from Broward County, Florida. Where is Equivant/Northpointe’s data? Who is training legal professionals to use COMPAS? How do I find out if my court is using COMPAS? The authors venture an unguarded opinion: this situation is a travesty. We need end-to-end transparency here at a minimum, and until we have it, skepticism of these tools is more than warranted.
Algorithmic Accountability
In January 2018, the New York City Council enacted a law to create
a task force that provides recommendations on how information on agency automated decision systems may be shared with the public and how agencies may address instances where people are harmed by agency automated decision systems.
This is unlikely to be the last legislation of its kind and it would be useful for the field to think a bit beyond the currently available datasets, public records laws, and avenues of accountability. What do you need access to?
Aside: Gerrymandering
In the past several years there has been an increasing interest in the mathematics of gerrymandering and other forms of election manipulation. In addition to the mathematical conversation, there are several active court cases. Whether or not these conversations connect for now at a theoretical level to those on quantitative fairness, they are likely to meet similar challenges in the policy sphere.
We raise a few questions in this direction:
- How does a court process technical results from a young field? Most papers on quantitative fairness are still somewhat methodologically innovative, only a handful of courses have been taught, there are few available books, no sense of curriculum.
- Does the conversation on gerrymandering connect in any meaningful way to the forms of quantitative fairness we’ve offered here? If not, are we missing something in our framework?
Intersectionality
In Demarginalizing the Intersection of Race and Sex: A Black Feminist Critique of Antidiscrimination Doctrine, Feminist Theory and Antiracist Politics, Kimberlé Crenshaw famously theorizes intersectionality, an analysis which avoids falling into a
single-axis framework (which) erases Black women in the conceptualization, identification and remediation of race and sex discrimination by limiting inquiry to the experiences of otherwise-privileged members of the group. In other words, in race discrimination cases, discrimination tends to be viewed in terms of sex- or class-privileged Blacks; in sex discrimination cases, the focus is on race- and class-privileged women
Crenshaw analyzes a series of failed Title VII cases, each involving black women who must pursue recourse against discrimination as black women which they are unable to establish simply as sex discrimination (since it does not apply to white women) or as race discrimination (since it does not apply to black men), and whose cases therefore failed. Crenshaw quotes the court in deGraffenreid vs General Motors:
Plaintiffs have failed to cite any decisions which have stated that Black women are a special class to be protected from discrimination. The Court’s own research has failed to disclose such a decision. The plaintiffs are clearly entitled to a remedy if they have been discriminated against. However, they should not be allowed to combine statutory remedies to create a new ‘super-remedy’ which would give them relief beyond what the drafters of the relevant statutes intended. Thus, this lawsuit must be examined to see if it states a cause of action for race discrimination, sex discrimination, or alternatively either, but not a combination of both.
and
The legislative history surrounding Title VII does not indicate that the goal of the statute was to create a new classification of ‘black women’ who would have greater standing than, for example, a black male. The prospect of the creation of new classes of protected minorities, governed only by the mathematical principles of permutation and combination, clearly raises the prospect of opening the hackneyed Pandora’s box.
In spite of the uphill legal battle, this line of thought has proved extremely productive in and beyond the legal sphere. Note the court’s apparent horror at the “Pandora’s box” of “mathematical principles of permutation and combination.” The court is asserting what are essentially principles of parsimony, familiarity, and intent. One can expect other “mathematical principles of permutation and combination” to meet some of the same challenges, and perhaps to re-open this “Pandora’s box” of intersectionality.
It is easy to imagine some formalizations of intersectional questions such as “how does being female modify the effect of being black” in probabilistic language (causal or not), which we decline to detail here. All of the examples in this article have been in “single-axis frameworks” and we want to point to that as a serious omission. It is possible to mislead with an overly simplified framework which becomes cumbersome or conceals issues when we reach the level of complexity which is relevant. From the quantitative fairness literature, see Kearns et al.. From the epidemiology literature, see Jackson et al. and Jackson.
While the standing of such questions with respect to Title VII may remain somewhat unsettled to this day, it is the authors’ opinion that analyses which move beyond protected classes will be more and more necessary. Even within a legal framework of protected classes, such analyses may be helpful in clarifying the edges of those classes, where interpretations frequently shift as to who is included.
For an example of these shifting boundaries, the question of whether sex discrimination language in the Civil Rights Act can be interpreted as providing recourse against anti-LGBT discrimination has been unsettled since the bill’s passage, and shifts with the political wind. Evidently protected classes are somewhat rickety and unstable political constructions, and it is the opinion of the authors that we need to pursue legal reforms that go a bit deeper than politically reversible guidance in the interpretation of a statute.
Those of us in the quantitative fairness conversation need to think about going beyond quantification of the principles which are already explicit in Title VII and instead push for new political solutions which are intersectional from the jump. That means among other things, catching up to the jurisprudential, theoretical, and activist conversations which continue to this day.
Health Disparities
The recent focus on quantitative fairness has been motivated by the increased use of automated procedures. Many researchers in this area come from machine learning, because of its development of such automated procedures. However, this article has also considered the definitions of fairness in examples of (mostly) human procedures, e.g. hiring. Here we connect to the public health study of disparities to bring in insights from this field.
Bailey et al. name three pathways from racism to health disparities: residential segregation, health care disparities, and discriminatory incarceration. Focusing on the second, we can consider health care utilization as the output from a complex (mostly) human procedure, our health care system. How can we evaluate its fairness along racial lines?
LeCook et al. name three definitions of health care utilization disparities. Each disparity definition corresponds violating a version of (conditional) statistical parity.
-
Unadjusted:
Requiring this be 0 is statistical parity.
-
Institute of Medicine [IOM 2003]:
Requiring this be 0 is conditional statistical parity.
-
Residual direct effect:
Requiring this be 0 is conditional statistical parity, conditioned on more data.
These three definitions are genuinely different. The Institute of Medicine (IOM) definition allows for utilization differences between racial groups that are explained by health care needs, but not by socioeconomic status. Connecting to our discussion of causal pathways above, we can consider current socioeconomic status a mediating variable between race and health care utilization. Though these disparity definitions are observational and not causal, in a somewhat vague sense, the IOM definition expresses that a path from race to utilization through socioeconomic status is unfair.
Directions
We’ve seen that there are many conflicting and non-obvious mathematical translations of political intuitions about fairness, and the list is by no means finished. It is the authors’ belief that a clearer understanding of these issues can enable conversations to move in several ways, and we close with a few takeaways.
Aporia
We believe it is valuable to highlight some of the confusion that exists in the definition of fairness and that this confusion has consequences. Returning to some of the questions of the introduction it is by no means clear that any formalization of fairness exhausts the moral and political sense of fairness. The concept’s unsettledness and resistance to formalization means a few concrete things:
- Beyond Law: We cannot assume that the formalization of fairness in 1960s Civil Rights legislation exhausts the concept of fairness.
- New Notions: We cannot assume that every principle or heuristic of fairness has already been articulated.
- No Saviors: We cannot assume that any formalization will remove the need for review and re-articulation.
For our understanding of this situation, the impossibility theorems we’ve described above play a small role compared to the simple plurality of notions. Which notions deserve to be animated with the normativity of moral judgments or the force of law? Which are to be pursued politically?
Discourse
The Interminable Argument
Much communication consists of taking one or another of these fairness concepts as obvious or axiomatic and asserting the violation of that principle as a political or moral gotcha. Formalization should not be regarded as a panacea in these debates but perhaps it can help to cement the points that:
- a lack of clarity can conceal a debate with real content and stakes
- differences in priorities and understandings of fairness are actually unresolved and in principle unresolvable without trade-offs
The Future of the Conversation
For more than fifty years, understandings of fairness have been shaped by the language of protected classes, disparate treatment and disparate impact. But in our discussion of intersectionality above, we’ve seen that there are some serious limitations to this framework, which remain unresolved to this day. As new understandings of fairness emerge from the quantitative conversation, we ought to consider:
- Are we framing a conversation we want to live with for fifty years?
- Whose concerns become easier or harder to articulate in a new framework?
Auditing Decision Procedures
Knowing that each definition of fairness has its trade-offs increases the interest in auditing decision procedures, possibly automatically, for various forms of unfairness. It is easy to imagine tools for pre-registration of decision procedures, which can then be measured by various fairness criteria in a responsive manner, enabling new kinds of intervention. It is not even necessary to resolve conflicts between formalizations before building such a tool, since nothing in principle prevents checking all of these conditions at once.
But we ought to beware, we urge anyone to consider as a thought experiment the explicit regulatory codification of fairness if it had happened five years before your favorite articles in the subject. We may have more reason to fear success than failure in this enterprise.
Increasing Transparency
It is possible and a hope of the authors that widespread awareness of the trade-offs and inconsistencies in the definitions of fairness may reduce the secrecy and publication bias in this field. This can proceed in a number of ways:
- By providing some ammunition to the case for legislating or otherwise forcing transparency in critical decision-making institutions and organizations.
- By creating an environment in which it might be imaginable for organizations to voluntarily discuss their own decisions and trade-offs, which may presently be either secret or intentionally unknown in order to avoid potential future leaks or subpoenas.
Pointedly, the existence of many plausible metrics of fairness allows us to pose explicitly the question of whether organizations are deliberately only publishing those metrics which reflect favorably on them, or whether they are suppressing any inquiry whatsoever to avoid a paper trail. In this article we have not taken a particularly adversarial analysis of the fairness landscape, but we encourage the reader to think through the way each definition of fairness can be gamed by malicious actors.
Beyond Statistics
As statistical thinkers in the political sphere we should be aware of the hazards of supplanting politics by an expert discourse. In general, every statistical intervention to a conversation tends to raise the technical bar of entry, until it is reduced to a conversation between technical experts. As a result, in matters of criminal justice, public health, and employment, the key stakeholders, whose stakes are human stakes, and who typically lack a statistical background, can easily fall out of the conversation.
So are we speaking statistics to power? Or are we merely providing that power with new tools for the marginalization of unquantified political concerns? What is the value of this quantitative fairness conversation to a person or community whose concerns will not be quantified for another decade, if ever?
Limits of Fairness
In our focus on quantitative and legal formalizations of fairness, we’ve deflected some fundamental questions about whether it is the right thing to formalize or pursue at all. We’ve talked a lot about fairness but have generally avoided talking about justice. To make the distinction between fairness and justice a little clearer, observe that our discussion of fairness has largely been symmetric and ahistorical. We’ve been focused on analyzing contemporary procedures for their fairness between groups, in a manner that hardly distinguishes those groups in their position of relative social hierarchy. We reserve the term justice for a discussion considering a broader set of issues, which may for example seek to rectify relations of domination between groups, and which considers history. Getting a boot off of your neck is different than asking for a new regulatory regime for footwear.
Here are a few of the questions we (and the field) have largely deflected:
- Does the concept of fairness derive its normativity from a more fundamental notion of justice, for which it is an imperfect proxy? The answer to this question determines whether fairness is worth formalizing and how much to make of paradox and aporia in our discussion.
- How does our discussion connect to concerns of justice which don’t fit naturally into the language of fairness?
- Pointedly, are there situations where it’s be right to be unfair? Not in order to embrace the opposite of fairness, but simply because fairness is the wrong abstraction? Could institutionalizing fairness requirements actually prevent meaningful progress towards justice?
- Does our evaluation of a decision procedure tacitly accept that this is the decision to be made, so long as it is done fairly? How does our work relate demands for reform, abolition, and alternative. To take a criminal justice example, do we want to equalize incarceration or do we want to eliminate it?
We certainly haven’t answered these questions here. To bring the matter down to earth, we can return to the question of interpreting disparate treatment and disparate impact in civil rights legislation. Do we read this language as naming forms of unfairness and providing tools to mitigate them? Or should we instead regard civil rights legislation as an approach to rectifying injustice against protected groups by offering some legal formalizations of unfairness and remedies? These interpretations are fundamentally different in their degree of commitment to the concept of fairness.
Parting Words
For the reader who is climbing the ladder to the contemporary quantitative conversation, we hope to have provided a bit of clarity. But in addition to the tutorial, we hope to have communicated a bit of methodological humility and wariness of technocracy. We are not one statistical innovation away from understanding, nor from justice.
For the non-quantitative reader, the take-away here might be that while this field gropes toward clarity, the moral and political fundamentals remain unsettled and in a sense unchanged. One can expect only a limited good from a quantitative conversation which tends to bracket political concerns. The reason to study quantitative fairness may in the end be to learn how to build the kind of organizations that can successfully question and respond to technocratic solutions.
La lutte continue.
Appendix 1: Other Resources
Rather than a formal bibliography we’ve decided to share a few resources.
Organizations
- Fairness, Accountability, and Transparency in Machine Learning (FAT/ML)
- Data for Black Lives (d4bl)
- Data & Society
- The AI Now Institute at New York University
Books
- Automating Inequality by Virginia Eubanks
- Algorithms of Oppression by Safiya Umoja Noble
- Weapons of Math Destruction by Cathy O’Neil
Course Materials
- A google doc of several courses.
- Moritz Hardt’s syllabus has a reading list.
Videos
Blogs
Software
- Fairness Measures: Datasets and software for detecting algorithmic discrimination
- Fairness comparison and the accompanying paper
- Aequitas
Appendix 2: List of definitions
An earlier version of this document which circulated in late 2017 was structured as a list of definitions. We’ve found that this format continues to be somewhat helpful and have reproduced the list below.
Metric Parities
Fairness for Decisions from the Confusion Matrix
- Equal True Positive Rates: $P[d=1 ~\vert~ Y=1, A=a] = P[d=1 ~\vert~ Y=1, A=a’]$
Equal False Negative Rates: $P[d=0 ~\vert~ Y=1, A=a] = P[d=0 ~\vert~ Y=1, A=a’]$
$d \perp A \ ~\vert~\ Y=1$ - Equal False Positive Rates: $P[d=1 ~\vert~ Y=0, A=a] = P[d=1 ~\vert~ Y=0, A=a’]$
Equal True Negative Rates: $P[d=0 ~\vert~ Y=0, A=a] = P[d=0 ~\vert~ Y=0, A=a’]$
$d \perp A \ ~\vert~\ Y=0$ - Equal Positive Predictive Values: $P[Y=1 ~\vert~ d=1, A=a] = P[Y=1 ~\vert~ d=1, A=a’]$
Equal False Discovery Rates: $P[Y=0 ~\vert~ d=1, A=a] = P[Y=0 ~\vert~ d=1, A=a’]$
$Y \perp A \ ~\vert~\ d=1$ -
Equal False Omission Rates: $P[Y=1 ~\vert~ d=0, A=a] = P[Y=1 ~\vert~ d=0, A=a’]$
Equal Negative Predictive Values: $P[Y=0 ~\vert~ d=0, A=a] = P[Y=0 ~\vert~ d=0, A=a’]$
$Y \perp A \ ~\vert~\ d=0$ - Overall Accuracy Equality: $P[d=Y~\vert~ A=a] = P[d=Y ~\vert~ A=a’]$ [Berk et al.]
- Statistical Parity: $P[d=1 ~\vert~ A=a] = P[d=1 ~\vert~ A=a’]$
$d \perp A$
Fairness for Scores
- Balance for the Positive Class: $E[S ~\vert~ Y=1, A = a] = E[S ~\vert~ Y=1, A = a’]$
If the score were 0-1 this is equal true positive rates (equivalently, equal false negative rates). - Balance for the Negative Class: $E[S ~\vert~ Y=0, A = a] = E[S ~\vert~ Y=0, A = a’]$
If the score were 0-1 this would be equal false positive rates (equivalently, equal true negative rates). - Calibration: $E[Y ~\vert~ S=s, A=a] = E[Y ~\vert~ S=s, A=a’]$
If the score were 0-1, this would be equal positive predictive values and equal negative predictive values. - AUC (Area Under Curve) Parity: the area under the receiver operating characteristic (ROC) curve should be the same across groups.
Conditional Independence
- Equalized Odds [Hardt et al.], Conditional procedure accuracy equality [Berk et al.]: $d \perp A \ ~\vert~\ Y$
- Conditional Use Accuracy Equality [Berk et al.]: $Y \perp A \ ~\vert~\ d$
- Conditional Statistical Parity: $P[d=1 ~\vert~ \textrm{Data}, A=a] = P[d=1 ~\vert~ \textrm{Data}, A=a’]$
$d \perp A\ ~\vert~\ \textrm{Data}$
Individual Fairness
- Fairness Through Unawareness: $d_i=d_j$ if $X_i=X_j$ for individuals $i,j$. This implies conditional statistical parity with $\textrm{Data}=X$. If the decision is a deterministic function of $X$, the two definitions are equivalent.
- Individual Fairness: $d_i \approx d_j$ if $X_i \approx X_j$ for individuals $i,j$. Friedler et al. define individual fairness using $X^{\textrm{construct}}$, the desired (but not perfectly observed) covariates at decision time.
Causality
- Individual Counterfactual Fairness: $d_i(a) = d_i(a’)$ for individual $i$
- Counterfactual Parity: $E[d(a)] = E[d(a’)]$
- Conditional Counterfactual Parity: $E[d(a) ~\vert~ \textrm{Data}] = E[d(a’) ~\vert~ \textrm{Data}]$. Conditioning on a lot of Data approaches individual counterfactual fairness. [Kusner et al.] Taking $\textrm{Data}=C$, if $d(a) \perp A | C \ \ \forall a$ (ignorability / unconfoundedness), this equivalent to conditional statistical parity.
-
No Direct Effect Fairness: $E[d(a)] = E[d(a’, M(a))]$ where $M$ are mediating variables
- No Unfair Path-Specific Effects: no average effects along unfair (user-specified) directed paths from $A$ to $d$ [Nabi and Shpitser]
-
No Unresolved Discrimination: there is no directed path from $A$ to $d$ unless through a resolving variable [Kilbertus et al.]
- Agency Parity: $E[d(\textrm{class}) - d(\textrm{no class}) ~\vert~ a] = E[d(\textrm{class}) - d(\textrm{no class}) ~\vert~ a’]$
NOTE: An earlier draft of this document circulated in December 2017, if you’re looking for that version or have cited it we maintain a copy here. Enormous thanks to everyone who commented on or contributed to that document.